

Un tema fundamental al que nos enfrentamos es conseguir que las Queries, Reports, Dashboards, List Views que construimos tengan el mejor rendimiento posible (muchas veces fueron escritas por otros compañeros hace un tiempo).
Desde hace un tiempo quería dedicar una serie de entradas al diseño y optimización de Queries y habiendo finalizado la certificación de Data Architecture and Designer es el momento ideal.
En esta serie de entradas trataré estos 8 aspectos:
- Qué son los índices y las estadísticas de Salesforce (esta entrada)
- Qué es y para qué se utiliza el Optimizador de Salesforce (esta entrada)
- Cuales son las reglas y condicionantes que utilizan el Optimizador para obtener un plan de ejecución de la query con el menor coste (esta entrada)
- Cuales son las reglas de oro básicas que debemos seguir (esta entrada)
- Como evaluar el rendimiento de una Query y herramientas que nos proporciona Salesforce para poderla tunear antes de publicarla (entradas siguientes)
- Mecanismos a nuestro alcance para mejorar el rendimiento sin afectar a nuestro modelo de datos (entradas siguientes)
- Mecanismos a nuestro alcance que requieren acciones sobre los datos para mejorar el rendimiento (entradas siguientes)
- Motivos por los cuales el rendimiento de una Query se degrada a lo largo del tiempo (entradas siguientes)
Y finalmente proporcionaré una herramienta propia, que nos permitirá detectar degradación de rendimiento en Queries de nuestra ORG.
Espero pues, que sea interesante y útil para todos los perfiles, tanto admins, desarolladores como arquitectos.
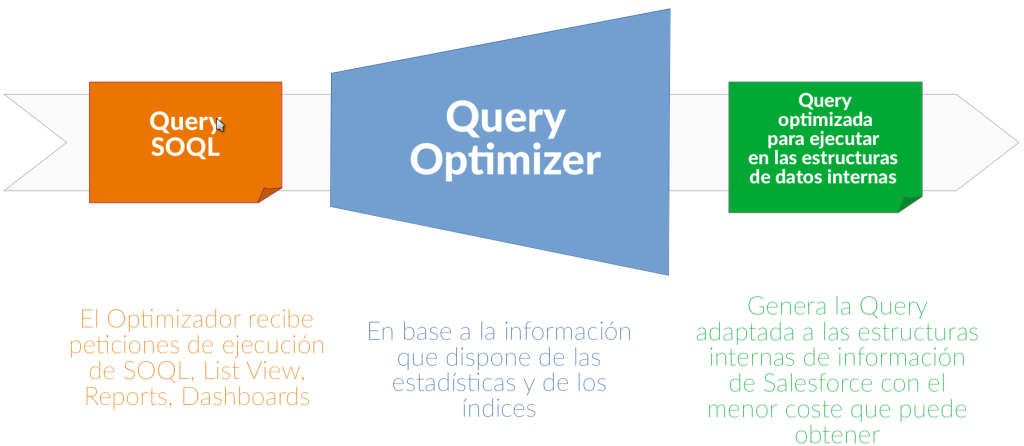
Qué es el Optimizador de Salesforce?
La mayoría de bases de datos relacionales del mercado muy conocidas como Oracle, PostgreSQL, etc., tienen un motor que al recibir una Query, la estudia, aplica mecanismos de optimización, y la ejecuta para que sea lo más eficiente posible con el menor coste.
Estos motores son denominados Cost-Based-Optimizers. Su funcionamiento a muy alto nivel es:
- Mientras insertamos o modificamos datos en una tabla, se recogen estadísticas sobre las datos que contienen las columnas de la tabla (número de registros, tipo del dato, repeticiones, etc.) y se registra tanto la distribución de los valores, como de los índices creados para las columnas.
- Al recibir una query, ya sea creada por un desarrollador, vía un Report, etc., el optimizador ejecuta unas reglas e intenta obtener el mejor plan de ejecución. Para ello, utiliza las estadísticas recopiladas y el uso de índices.
- El mejor plan es siempre el que tenga un menor coste.
¿Y cómo calcula este coste? Buenísima pregunta, porque ahí está la madre del cordero:
- El optimizador evalúa las condiciones existentes en la sentencia
WHERE, con especial atención a los operadores utilizados (=, <, >, !=, LIKE, OR, AND, etc.) - Su obsesión es saber si existe un plan de ejecución más eficiente que recorrer toda la tabla. Es decir, utilizando los índices y sus estadísticas, ¿puede obtener una query optimizada de menor coste?
- Cuando esto sucede, la query recibe la denominación de Selectiva, o que tiene un grado de Selectivity.
Esteve, pero entonces, ¿son importantes las estadísticas y los índices en Salesforce entonces? Absolutamente, veamos que son para comprenderlo.
¿Qué es un índice y que son las estadísticas?
Un índice no es nada más que una estructura de información (imagínate una tabla) donde se indica en que registro puedes encontrar cada ocurrencia de datos.
Las estadísticas indican como están distribuidos los valores en las tablas índices, y el optimizador utiliza estas tablas para lanzar y ejecutar pre-queries.
Las estadísticas en Salesforce se actualizan cada noche (en versiones anteriores era semanal), por lo que si produces cambios masivos en tus datos debes tenerlo en cuenta.
Veamos un ejemplo: supongamos que una tabla Animales__c contiene un campo, denominado Tipo_Animal__c para el cual tenemos un índice. El contenido de este índice sería:
- Gato los puedes encontrar en los registros 1, 12, 2056 y 42134.
- Perro los puedes encontrar en los registros 2, 15 y 245.
- Conejo Enano los puedes encontrar en los registros 3, 20, 36, 47, 90 y 25000.
Y sus estadísticas serían:
- Gato: 4
- Perro: 3
- Conejo enano: 6
Esto permite que para un Query como SELECT Nombre__c FROM Animales__c WHERE Tipo_Animal__c = "Gato" no haga falta leer todos de los registros de la tabla buscando aquellos registros en cuyo campo tipo tiene un Gato, sino que, accediendo directamente a los 4 registros concretos (1, 12, 2056 y 42134), podremos obtener la información.
Por supuesto una índice contiene algo más de información, como puedes ver en la imagen de la documentación oficial:

Ah, una cosita más…el Optimizador de Salesforce además tiene en consideración 3 puntos adicionales para ser más eficiente:
- Multitenant Statistics: como Salesforce es una plataforma multitenant, recoje estadísticas adicionales para particularizar sobre los datos de cada tenant.
- Composite Index Joins: cuando el
WHEREcontiene varias condiciones, el optimizador considera la Selectivity de cada índice pero también la intersección de índices formados por 2 campos. - Sharing Filters: dado que Salesforce permite la creación de un modelo de compartición de datos, este aspecto puede afectar al filtrado de datos, y el optimizador también lo tiene en cuenta.
Y aquí, ya te anticipo un tema muy relevante, si conoces bien las reglas y condiciones con las que trabaja el Optimizador, podrás conseguir Queries con buen rendimiento, y sin conocerlas seguramente no entenderás porque algunas Queries van bien, otras mal, y porque se degrada el rendimiento a medida que pasa el tiempo.
Reglas y condicionantes para el Optimizador
Para que el Query Optimizer de Salesforce pueda escoger el plan de ejecución de coste bajo, en tus Queries, las reglas de ORO son 2:
- Los campos sobre los que filtras en el
WHEREdeben estar indexados (tanto campos Standard como Custom). - Utilizar los índices debe ser más eficiente que recorrer la tabla entera. Si recorrer el índice supone un esfuerzo importante, el optimizador decidirá que no vale la pena utilizarlo, y recorrerá la tabla entera (=Full Scan).

Por tanto, los campos que aparecen en la cláusula WHERE deben estar indexados, y que el índice sea mejor que recorrer la tabla entera (Full Scan), en cuyo caso el optimizador obtendrá un Coste inferior a 1, y en este caso decimos que la Query es Selectiva.
¿Pero, y qué cálculos realiza el Optimizador? Bien bien, vamos bien.
Las reglas del optimizador
Los cálculos que realiza el optimizador, mediante pre-queries son conocidos y son los siguientes:
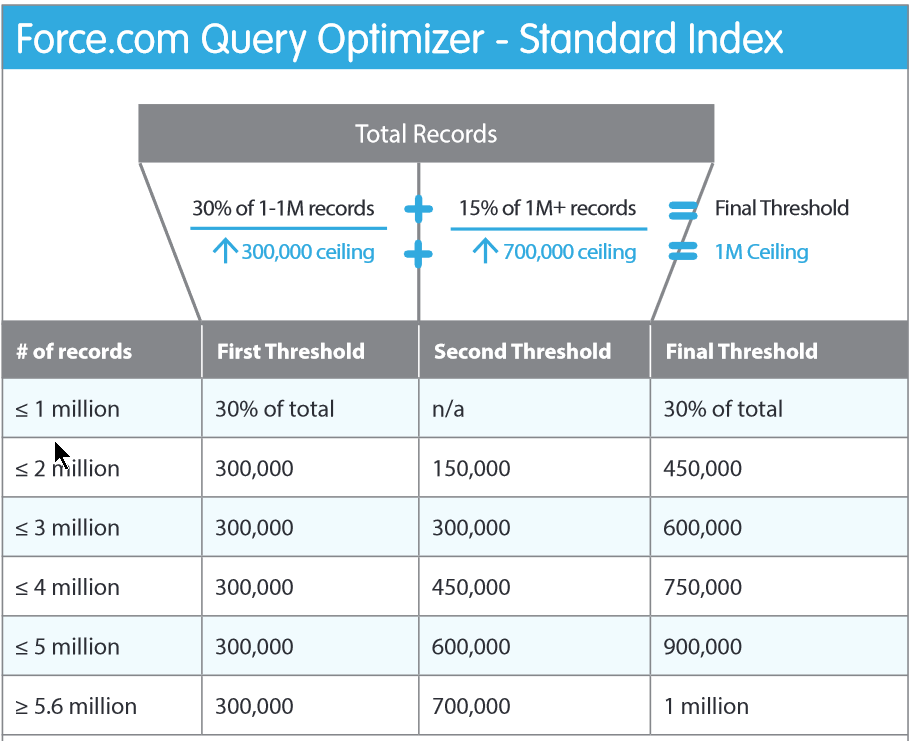
- Si el campo filtrado es un campo de Standard de Salesforce, el optimizador lanza una pre-query contra el índice. Si el número de registros que obtiene es inferior al 30% del primer Millón + 15% del volumen completo restante, hasta un máximo de 1 Millón de registros (300.000 + 700.000), el optimizador considera adecuado usar el índice, y construye la Query optimizada usando la estructura del índice
- Si el campo filtrado es un campo Custom que contiene un índice, lanza la misma Pre-query y calcua el número de registros, y si es inferior a la suma del 15% del primer Millón + 5% del volumen completo restante, hasta un máximo de 333.333 registros (=100.000 + 233.333), el optimizador considera adecuado usar el índice y construye la Query optimizada usando la estructura del índice

Veamos un par de ejemplos prácticos:
- Supongamos el objeto Lead que en nuestra ORG contiene 3,5 millones de registros
- Al filtrar en el
WHEREpor el campo OwnerID que es un campo Standard que está indexado, el índice debe devolver un número inferior al 30% de 1 Millón + 15% de 2,5 millones = 300.000 + 375.000) 675.000 registros, o en caso contrario el optimizador descartará el índice y realizará un Full Scan - Al filtrar en el
WHEREpor un campo Custom (Scoring de un Lead) que está indexado, el índice debe devolver un número inferior al 10% de 1 Millón + 5% del volumen restante de 2,5 millones = 100.000 + 125.000) 225.000 registros, o en caso contrario el optimizador descartará el índice y realizará una operación de Full Scan sobre el objeto
Si en la cláusula WHERE aparecen los operadores AND, OR, LIKE, el optimizador realiza otras operaciones de cálculo:
- Para AND: su máximo número de registros aceptado usando el índice es el doble de la límites de cada índice, y el número de registros que aparezca de la intersección de ambos
- Para OR: aplica el cálculo del índice simple y además la suma de ambos
- Para LIKE: examina las 100.000 primeras filas y toma la decisión en función de los resultados obtenidos
Y de aquí aparece un nuevo concepto: ¿Qué campos se indexan o como podemos crear nuevos índices?
¿Qué campos se indexan? ¿Cómo crear otros índices?
Lo ideal sería, indexar todos los campos o que se indexaran todos por defecto, y todos felices y contentos, ¿no? Desafortunadamente, esto no es posible, porque crear/mantener un índice requiere de un consumo de recursos elevado y ocurre con frecuencia, cuando añadimos/modificamos/borramos datos.
Debes tener en cuenta que cuando cambias un 25% de los datos de un objeto, Salesforce rehace por completo las estadísticas para ese objeto, y por tanto, deberá reconstruir gran parte de la información de los índices.

Además, al regenerar varios índices, se pueden producir cuellos de botella conocidos como Index Skew y Row Locking.
El primero consiste en que el índice es obeso, contiene un número demasiado elevado de valores se contemplan en el índice, y el segundo consiste en la competición y bloqueo de los registros, porque hay un proceso que intenta actualizar el índice y otros procesos que pretenden actualizar los registros del objeto.
Campos indexados por defecto
Por tanto Salesforce ya indexa por defecto los siguientes campos:
- Campos Standard:
- Id
- Name
- OwnerId
- CreatedDate
- SystemModstamp
- RecordType
- Master-detail fields
- Lookup fields
- Division (si se utiizan)
- Email (solo en Contact y en Lead)
- Campos Custom:
- Campos Unique
- External ID (recuerda que deben ser Number, Auto Number, Email ó Text)
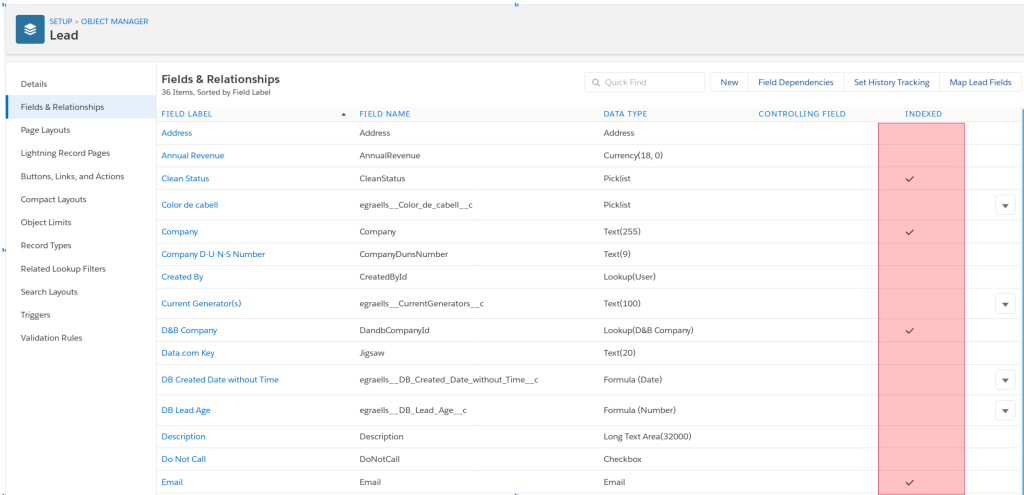
Pero no es necesario que memorices esta lista de memoria, o si Salesforce la amplia o la reduce, en la descripción de todos los objetos de la ORG, se muestran aquellos campos que están indexados, y verás cuales de los standard y cuales de los custom lo están.
Fíjate en la imagen siguiente y en la columna que te destaco en rojo:
Creación de Índices adicionales
Aunque Salesforce indexa ciertos campos, casi con total seguridad tendrás la necesidad de crear índices sobre campos que hemos añadido a objetos Standard y también objetos Custom.
Por ello, podemos solicitar la creación de nuevos índices, mediante la apertura de un caso al Soporte de Salesforce (te pedirán varia información para entender la necesidad y crear el índice adecuado).
Estos índices se replican en todos los Sandbox, para que todos los participantes del proyecto, puedan evaluar el rendimiento de las queries, desde cualquier entorno.
¿Qué podemos solicitar exactamente?
- Podemos solicitar la creación de índices en campos Custom
- Podemos solicitar índices compuestos por 2 campos, con la versatilidad que el segundo campo si puede contener valores NULLs por defecto, aunque no es aplicacle a Picklist, External IDs y campos Lookup/Master-Detail
- Podemos solicitar que el índice contenga valores NULL (debe solicitarse al Soporte de Salesforce explícitamente). Esto no aplica a picklists, External IDs, y campos Lookup/Master-Detail, pero como puedes crear campos compuestos, donde el segundo campo puede contener Nulls, puedes trabajar con el soporte de Salesforce para conseguir un campo indexado.
- Podemos solicitar la creación de índices sobre campos fórmulas (no todas – deben cumplir ciertas condiciones – lo veremos en la siguiente entrada)
Las opciones de 2, 3 y 4, en mi experiencia, son poco conocidas, por lo que es importante que las tengas presentes, se las recuerdes al equipo y las implantes con la ayuda del soporte de Salesforce.

¿Qué tipos de campos aceptan índices y cuales no?
Inicialmente, todos los tipos de campos excepto los que nombro a continuación permiten la creación de índices Custom. No se permite la creación de campos índices sobre los tipos siguientes:
- Multi-select Picklists
- Currency fields en una ORG con Multi-Currency activado
- Long text
- Binary fields (Blob, File y los Encrypted)
- Fórmula No-Determinísticas (te lo explico a continuación)
Para todos ellos, te recomiendo que crees fórmulas, que no muestres en los Layouts, que generen valores equivalentes (funciones de Hash o parecidas) que mediante fórmula determinísticas, puedas indexar.
Para que podamos solicitar un índice sobre una fórmula, esta, debe cumplir las siguientes características y entonces recibe nombre de fórmula determinística:
- La fórmula no contiene campos de referencia de otros objetos.
- La fórmula no hace referencia a otras fórmulas que son NO-determinísticas.
- Hay determinados campos, que no están publicados en la documentación de Salesforce que no se permiten en las fórmulas y que se van eliminando a medida que avanzan las versiones del producto (por ejemplo en Spring’12 createdById no se aceptaba pero en Summer’12 yo lo era). Compruébalo con el soporte de Salesforce cuando hagas la petición.
- La fórmula no contiene la función TEXT(<picklist-field>).
- Si la fórmula referencia a un campo Lookup, este debe estar marcado con la opción «Clear the value of this field».
- La fórmula no utiliza campos Owner, Id, de tipo Autonumber, Divisions, LastModifiedDate ó campos de auditoría de las tablas excepto CreatedDate y CreatedByID.
- Si la fórmula utiliza alguno de los siguientes campos de estos determinados objetos:
- Opportunity: Amount, TotalOpportunityQuantity, ExpectedRevenue, IsClosed, IsWon.
- Case: ClosedDate, IsClosed.
- Product: ProductFamily, IsActive, IsArchived.
- Solution: Status.
- Lead: Status.
- Activity: Subject, TaskStatus, TaskPriority.
Atención si la fórmula se modifica posteriormente a la creación del índice, el índice queda deshabilitado y hay que contactar nuevamente con el Soporte de Salesforce para reactivarlo.
Condicionantes por los cuales nuestra Query no puede ser Selectiva

Existe un conjunto de condicionantes que provocan que el optimizador marque siempre la query como no Selectiva:
- Gran cantidad de datos que implique que las pre-queries superan siempre los Threadsholds del Query Optimizer. Es difícil evitar este condicionante, y seguramente requerirá de otras acciones que veremos en artículos más adelante o re-escribir la query.
- Tener gran cantidad de registros en la papelera y no haber especificado la cláusula IsDeleted=false en la proyección del WHERE.
- Utilizar el operador LIKE ‘%texto’ para buscar patrones de texto.
- Usar operadores negativos (mejor utilizar = ó IN ó utilizar una fórmula con índice)
- Condiciones con Joins complejos que requieran de muchas operaciones. Este condicionante se puede trabajar con el soporte de Salesforce.
Conclusiones

Si tienes como mascota un conejo enano, no esperes que venga cuando le llamas, te lo digo por experiencia.
En cuanto a optimización de Queries debes recordar estos puntos básicos:
- Sin índices no hay Queries con buen rendimiento, es decir, no hay Queries Selectivas, que tienen Coste < 1
- Hay campos indexados por defecto, pero podemos y seguramente debemos crear nuevos índices custom
- Conocer las reglas y condicionantes con las que se ejecuta el Optimizador son primordiales para optimizar nuestras Queries
- Como el volumen de nuestros objetos cambia, los índices cambian, las estadísticas, y las Queries se pueden degradar en el tiempo (te suena: …antes iba bien pero ahora tarda mucho…)
A todo esto, aún no hemos visto, como obtener el coste que el Optimizador asigna a la Query con la que estamos trabajando. Por eso en esta siguiente entrada, te muestro las herramientas que te permitirán evaluar el coste de las consultas en tu ORG, antes que sea demasiado tenga y tengas problemas de rendimiento.
Espero que esta serie te sea de ayuda.
Enlaces interesantes
- Get Started with Salesforce Optimizer
- Force.com Query Optimizer Secrets You Can Use Today
- Make a SOQL Query Selective
- Query and Search Optimization Cheat Sheet
- Best Practices for Deployments with Large Data Volumes (Indexes)
- Video Alberto Lozano sobre Optimización de queries muy completo
- Trailhead: Write Efficient Queries

Replica a Israel Devesa cuevas Cancelar la respuesta